浅析JDK1.8 ConcurrentHashMap源码,不得不感慨一下Doug Lea真的太强了!
写在开篇
先贴张图看下ConcurrentHashMap JDK 1.8的结构: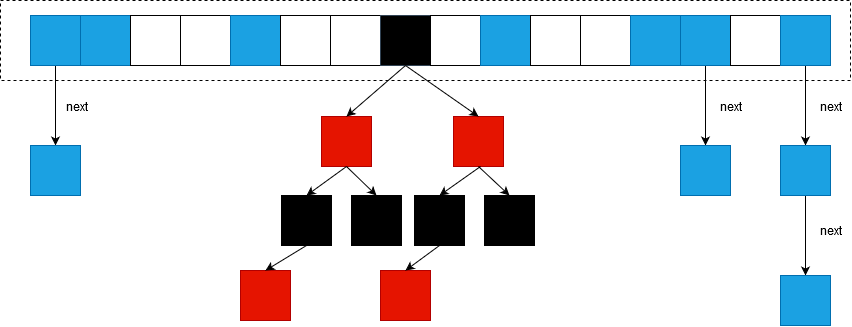
先大体介绍一下:ConcurrentHashMap JDK1.8抛弃了JDK1.7中原有的Segment分段锁,而采用了CAS + synchronized来保证并发安全性。
类的继承关系
1 | public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> |
继承于抽象的AbstractMap,ConcurrentMap,Serializable这两个接口。
重要属性
1 | /** |
Node
Node:将JDK1.7中存放数据的HashEntry改为Node。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
// ...
}
ForwardingNode:一个特殊的 Node 结点,hash值为-1,作为一个占位符放在原数组中表示当前结点在nextTbale中已经被移动。1
2
3
4
5
6
7
8
9
10
11
12
13static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
// ...
Node<K,V> find(int h, Object k) {
// 扩容时,get()会调用到,在下文会分析
}
}
构造方法
ConcurrentHashMapJDK1.8构造方法中,是还没有初始化Node[]的,没有参数的构造方法是个空方法,如下:1
2public ConcurrentHashMap() {
}
其余的构造方法都只是设置了sizeCtl,举个例子:1
2
3
4
5
6
7
8public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
put()
1 | public V put(K key, V value) { |
初始化数组
1 | private final Node<K,V>[] initTable() { |
treeifyBin()
treeifyBin()不一定就会进行红黑树转换,也可能是仅仅做数组扩容。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY) // table长度小于最小的长度
tryPresize(n << 1); // 扩容,调整某个桶中结点数量过多的问题
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) { // 转为红黑树的情况
synchronized (b) { // 加锁同步
if (tabAt(tab, index) == b) { // 再次确认Node对象还是原来的那一个
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) { // 遍历桶中结点
// 创建TreeNode结点
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null) // 该结点前驱为空
hd = p; // 设置为头结点
else
// 尾结点的next设为p
tl.next = p;
// 尾结点赋值为p
tl = p;
}
// 设置table中下标为index的值为hd
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
扩容
什么时候会扩容
- addCount():使用put()插入元素时会调用addCount(),检查是否需要扩容
- tryPresize():
- 链表转红黑树过程,table容量小于MIN_TREEIFY_CAPACITY时
- 调用putAll()一次性加入大量元素时,会触发扩容
- helpTransfer():使用put()插入元素时,发现Node为fwd时,会协助扩容
addCount()
1 | private final void addCount(long x, int check) { |
resizeStamp()
在上面的代码中调用到这个方法,我们来看一下:1
2
3
4
5
6
7private static int RESIZE_STAMP_BITS = 16;
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
Integer.numberOfLeadingZeros(n):计算n转换成32位二进制之后1前面有几个0。因为ConcurrentHashMap的容量一定是2的幂次方,所以不同的容量n前面0的个数一定不同,这样可以保证是在原容量为n的情况下进行扩容。
1 << (RESIZE_STAMP_BITS - 1):即是1<<15,表示为二进制即是高16位为0,低16位为1:1
0000 0000 0000 0000 1000 0000 0000 0000
所以resizeStamp()的返回值(rs):高16位置0,第16位为1,低15位存放当前容量n,用于表示是对n的扩容。
rs与RESIZE_STAMP_SHIFT配合可以求出新的sizeCtl的值,分情况如下:
- sc < 0:已经有线程在扩容,将sizeCtl+1并调用transfer()让当前线程参与扩容
- sc >= 0:没有线程在扩容,使用CAS将sizeCtl的值改为(rs << RESIZE_STAMP_SHIFT) + 2)
rs即resizeStamp(n),记temp=rs << RESIZE_STAMP_SHIFT。如当前容量为8时rs的值:1
2
3
4
5
6//rs
0000 0000 0000 0000 1000 0000 0000 1000
//temp = rs << RESIZE_STAMP_SHIFT,即 temp = rs << 16,左移16后temp最高位为1,所以temp成了一个负数
1000 0000 0000 1000 0000 0000 0000 0000
//sc = (rs << RESIZE_STAMP_SHIFT) + 2)
1000 0000 0000 1000 0000 0000 0000 0010
那么在扩容时sizeCtl值的意义:高15位为容量n,第16位位并行扩容线程数+1。
tryPresize()
和addCount()的实现很相似,不多赘述。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45private final void tryPresize(int size) { // size传入时已*2
// c:size 的 1.5 倍,再加 1,再往上取最近的 2 的 n 次方
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) { // 没有其他线程在初始化、扩容
Node<K,V>[] tab = table; int n;
// 这个if分支和前面的初始化数组的代码基本上是一样的,在这里,我们可以不用管这块代码
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
int rs = resizeStamp(n);
if (sc < 0) { // 已有线程在进行扩容工作
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 将sizeCtl加1,然后执行transfer(),此时nextTab不为null
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 将sizeCtl设置为(rs << RESIZE_STAMP_SHIFT) + 2
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 调用transfer(),此时nextTab参数为null
transfer(tab, null);
}
}
}
helpTransfer()
和addCount()的实现很相似,不多赘述。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) { // 已有线程在进行扩容工作
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
// sizeCtl加1,表示多一个线程进来协助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
transfer()
我们可以看到上面三种方法最后都调用了transfer(),显然transfer()才是真正进行并行扩容的地方。
当外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab参数为null,之后再调用此方法的时候,nextTab不会为null。 理解为有n个迁移任务,让每个线程每次负责一个小任务,每做完一个任务再检测是否有其他没做完的任务。
- Doug Lea使用了一个stride(步长),每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
- transfer()并没有实现所有的迁移任务,每次调用这个方法只实现了transferIndex往前stride个位置的迁移工作,其他的需要由外围来控制。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { // 参数为原数组,扩展数组 |
代码有点长,在这里小结一下,这个方法主要分成两个部分:
- while循环:确定当前线程要迁移的桶的范围以及通过更新i的值确定当前范围内下一个要处理的结点
- 其他代码:转移桶中结点
get()
这里我们主要关注扩容时,get()怎么做:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0) // 在迁移或都是TreeBin
// 调用节点对象的find方法查找值
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
内部类ForwardingNode中的find():
这里的查找,是去新Node数组nextTable中查找的,过程与HashMap相似,不多赘述。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
容器结点数量
统计容器大小其实是用了两种思路:
- CAS方式直接递增:在线程竞争不大的时候,直接使用CAS操作递增baseCount值即可,这里说的竞争不大指的是CAS操作不会失败的情况
- 分而治之桶计数:若出现了CAS操作失败的情况,则证明此时有线程竞争了,计数方式从CAS方式转变为分而治之的桶计数方式
countCell
这里解释一下什么是计数桶: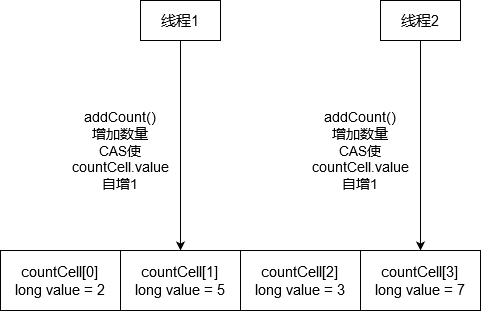
这样减少了线程的冲突,查询总数的时候sum = countCell[0] + countCell[1] + countCell[2] + countCell[3]
在设计中,使用了分而治之的思想,将每一个计数都分散到各个countCell对象里面(下面称之为桶),使竞争最小化,又使用了CAS操作,就算有竞争,也可以对失败了的线程进行其他的处理。乐观锁的实现方式与悲观锁不同之处就在于乐观锁可以对竞争失败了的线程进行其他策略的处理,而悲观锁只能等待锁释放,所以这里使用CAS操作对竞争失败的线程做了其他处理,很巧妙的运用了CAS乐观锁。
代码实现
CounterCell:1
2
3
4.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
接着补上addCount()我们在上面跳过的部分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
/**
* 进入此语句块有两种可能
* 1.counterCells被初始化完成了,不为null
* 2.CAS操作递增baseCount值失败了,说明有竞争
*/
CounterCell a; long v; int m;
// 标志是否存在竞争
boolean uncontended = true;
/**
* 条件:
* 1.计数桶是否还没初始化,若as == null,进入语句块
* 2.计数桶是否为空,若桶为空进入语句块
* 3.用一个线程变量随机数,与上(桶大小-1),若桶的这个位置为空,进入语句块
* 4.到这里说明桶已经初始化了,且随机的这个位置不为空,尝试CAS操作使桶加1,失败设置uncontended值并进入语句块
*/
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
// 初始化或扩容counterCell[]
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
// ...
}
初始化CounterCell[]
1 | private final void fullAddCount(long x, boolean wasUncontended) { |
扩容CounterCell[]
从上面的分析中我们知道,计数桶初始化之后长度为2,在竞争大的时候肯定是不够用的,所以一定有计数桶的扩容操作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85private final void fullAddCount(long x, boolean wasUncontended) {
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
boolean collide = false;
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
// 计数桶初始化好了,进入该if块
if ((as = counterCells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) { // 从计数桶数组随机选一个计数桶,若为null表示该桶位还没线程递增过
if (cellsBusy == 0) { // 计数桶数组busy状态是否被标识
// 创建一个计数桶
CounterCell r = new CounterCell(x);
// 标志计数桶数组busy状态
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try {
CounterCell[] rs; int m, j;
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
// 将刚刚创建的计数桶赋值给对应位置
rs[j] = r;
created = true;
}
} finally {
// 标识不busy了
cellsBusy = 0;
}
if (created)
break;
continue;
}
}
collide = false;
}
else if (!wasUncontended)
wasUncontended = true;
// 走到这里代表计数桶不为null,尝试递增计数桶
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
else if (counterCells != as || n >= NCPU)
collide = false;
// 若CAS操作失败了,到了这里,会先进入一次下面的if块,然后再走一次刚刚的for循环
// 若是第二次for循环,collide=true,则不会走进去
else if (!collide)
collide = true;
// 计数桶扩容,一个线程若走了两次for循环,也就是进行了多次CAS操作递增计数桶失败了
// 则进行计数桶扩容,CAS标示计数桶busy中
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
// 确认计数桶还是同一个
if (counterCells == as) {
// 将长度扩大到2倍
CounterCell[] rs = new CounterCell[n << 1];
// 遍历旧计数桶,将引用直接搬过来
for (int i = 0; i < n; ++i)
rs[i] = as[i];
// 赋值
counterCells = rs;
}
} finally {
// 取消busy状态
cellsBusy = 0;
}
collide = false;
continue;
}
// 重新设置线程随机数
h = ThreadLocalRandom.advanceProbe(h);
}
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
// 初始化计数桶...
}
// 初始化计数桶没抢到计数桶数组busy资格才能走到这
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break;
}
}
小结一下:
- 在CAS操作递增计数桶失败了3次之后,会进行扩容计数桶操作,注意此时同时进行了两次随机定位计数桶来进行CAS递增的,所以此时可以保证大概率是因为计数桶不够用了,才会进行计数桶扩容
- 计数桶长度增加到两倍长度,数据直接遍历迁移过来,由于计数桶不像HashMap数据结构那么复杂,有hash算法的影响,加上计数桶只是存放一个long类型的计数值而已,所以直接赋值引用即可
参考:
https://blog.csdn.net/qq_41737716/article/details/90549847
https://blog.csdn.net/tp7309/article/details/76532366
https://www.jianshu.com/p/81d848ea6c1a

