现象
伴随着服务线上流量高峰时段,一台服务器出现MDC内存告警,而且在流量下降后还是没有停止告警的情况。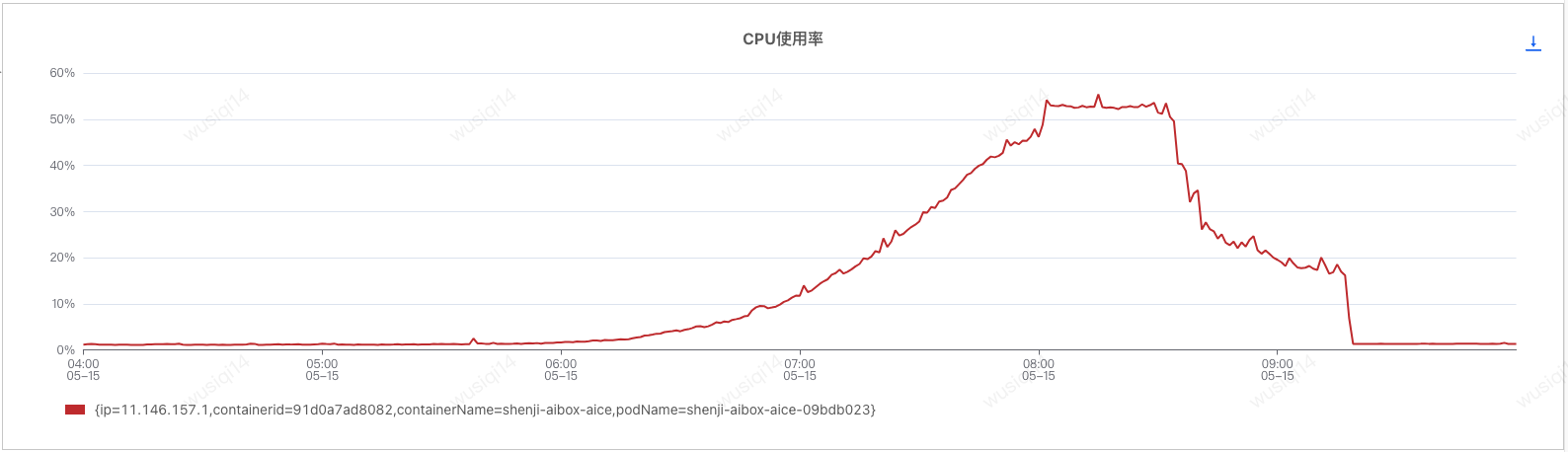
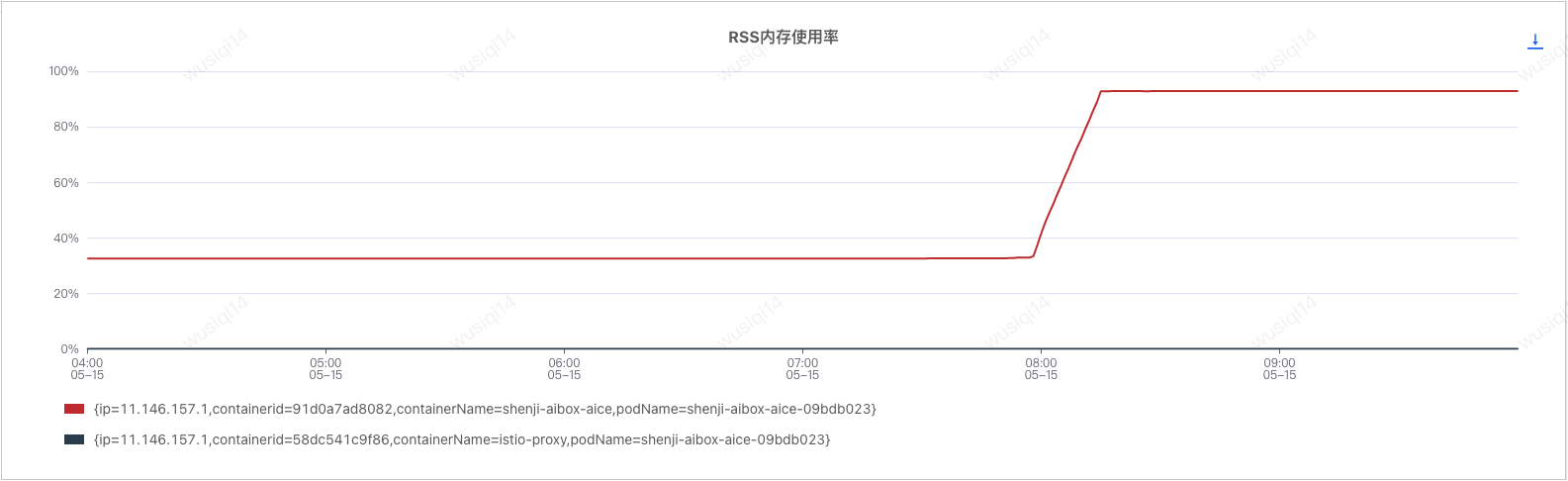
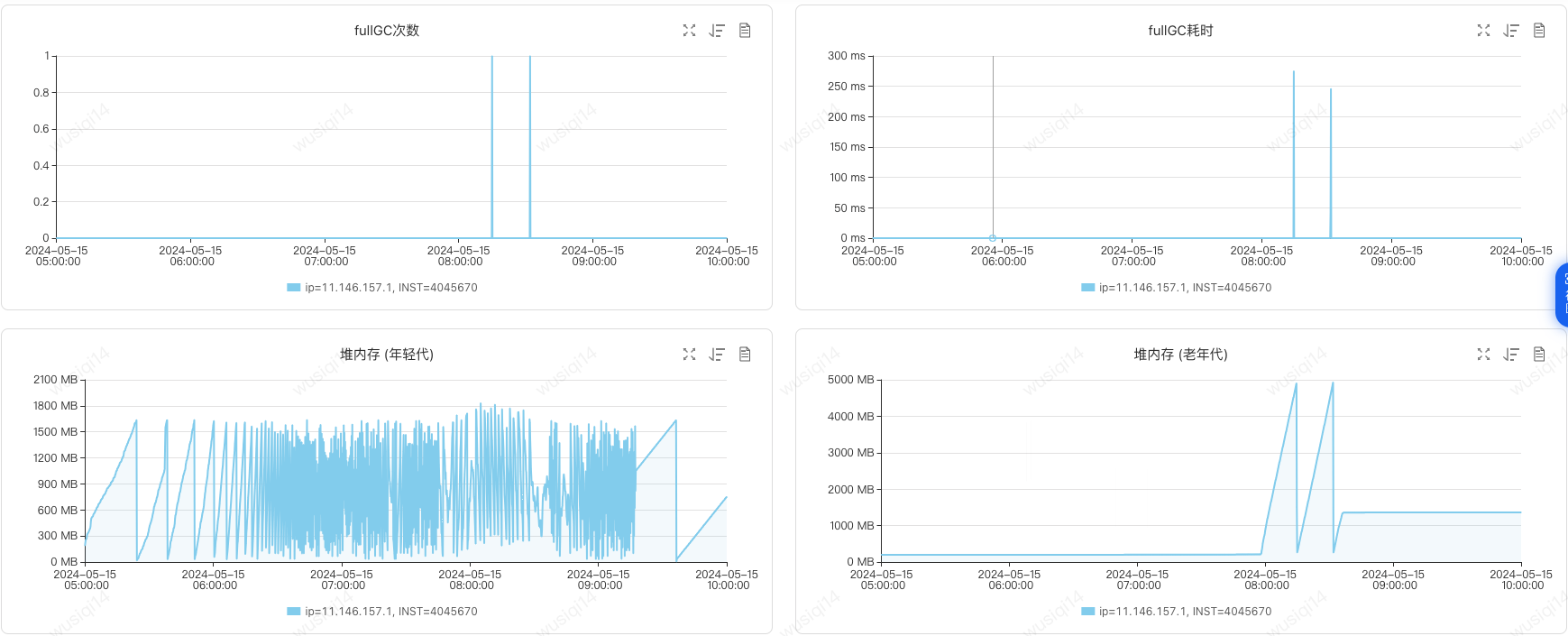
在JVM监控中明显的看到由于业务流量升高,导致Young GC次数增加,并且出现对象逐渐从年轻代晋升到老年代的情况,最终触发了两次Full GC。Full GC后老年代使用空间为390M,意味着此时绝大多数(92% = 4900-390/4900M)的对象已经不再存活,也就是说生命周期长的对象占比很小。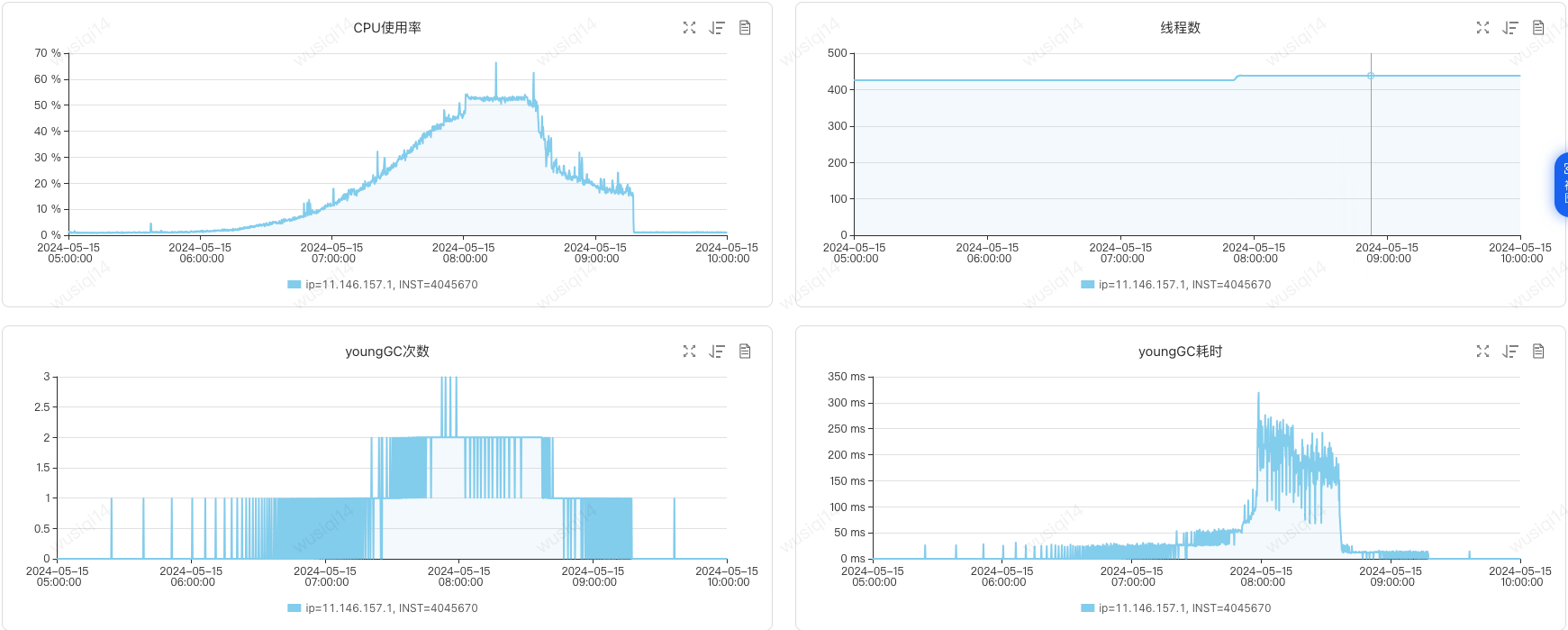

问题一:老年代堆内存稳定后,还在告警
对4C8G的容器分配了8G的堆内存大小,触发Full GC阈值不合理,总内存超过告警比例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25-Xms8192M
-Xmx8192M
-XX:NewSize=2048M
-XX:MaxNewSize=2048M
-XX:+UseConcMarkSweepGC
-XX:ParallelGCThreads=8
-XX:CICompilerCount=2
-XX:ReservedCodeCacheSize=512M
-XX:MaxMetaspaceSize=512M
-XX:MetaspaceSize=512M
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=80
-XX:CMSFullGCsBeforeCompaction=5
-Dfastjson.parser.autoTypeSupport=true
-Xloggc:/export/Logs/gc-%t.log
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintTenuringDistribution
-XX:+PrintHeapAtGC
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=50M
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/export/Logs/heapdump.hprof
问题二:频繁Full GC
DAY 1
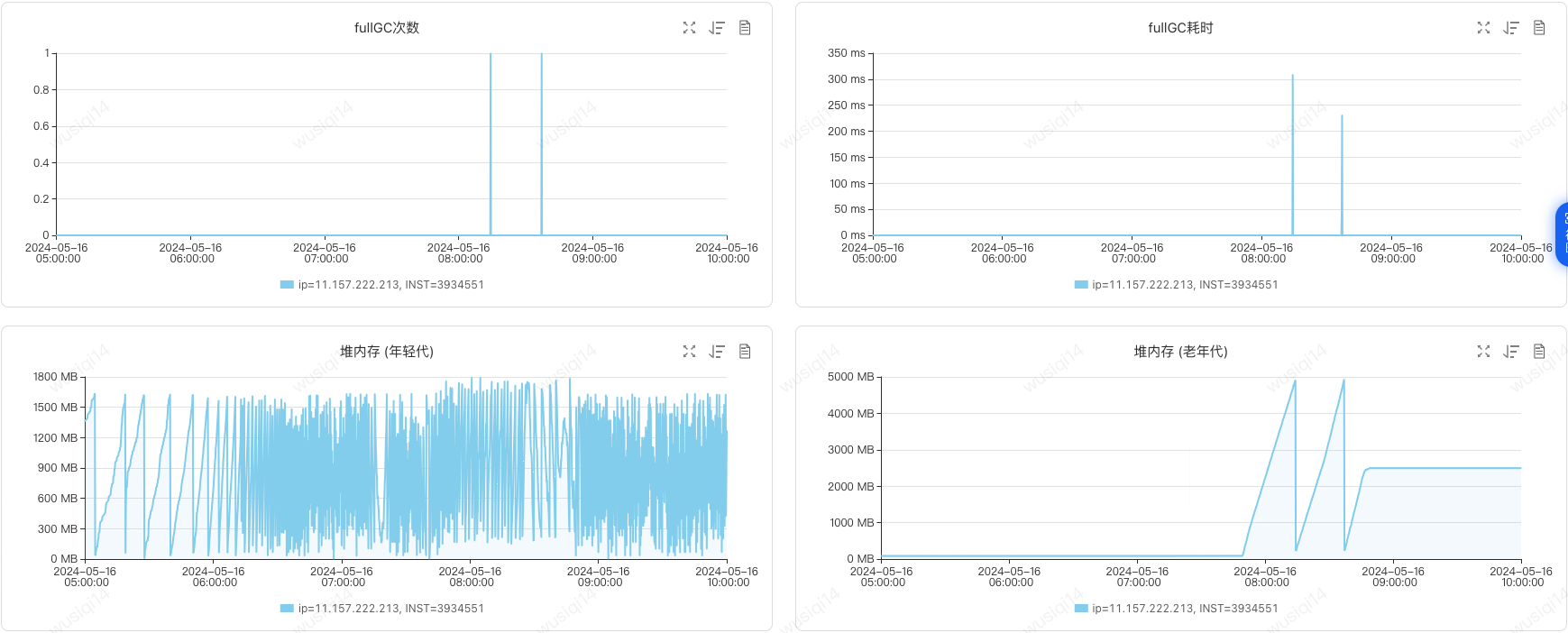
分析在8:14和8:32触发了两次Full GC,对于我们来说需要避免新生代的对象进入老年代,尽量让对象留在新生代里被回收掉,这个触发Full GC的间隔太过于频繁了。
分析GC日志发现,对于Concurrent Mark Sweep垃圾回收器对象晋升到老年代阈值中默认值为6,逐渐有对象晋升到老年代,导致触发Full GC。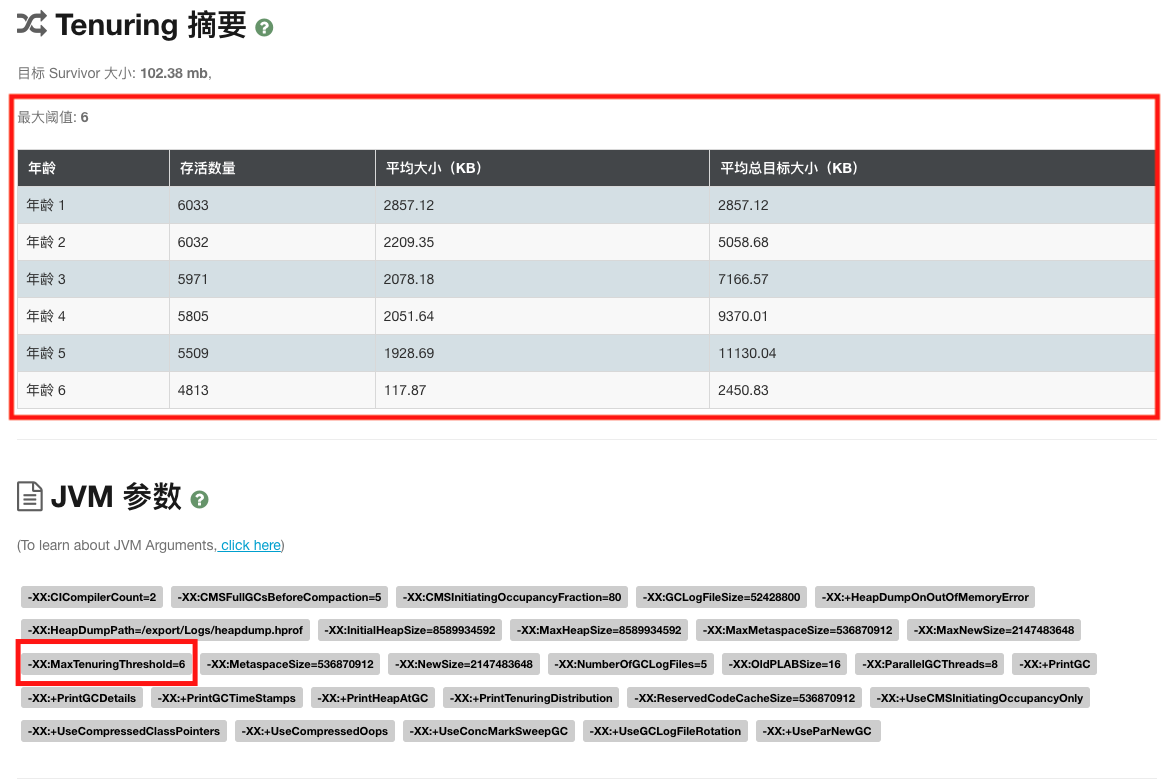
处理调整晋升到老年代阈值为15,尽量避免新生代对象晋升到老年代,避免触发Full GC。
-XX:MaxTenuringThreshold=15
DAY 2
分析第二天业务高峰还是出现了一样的问题。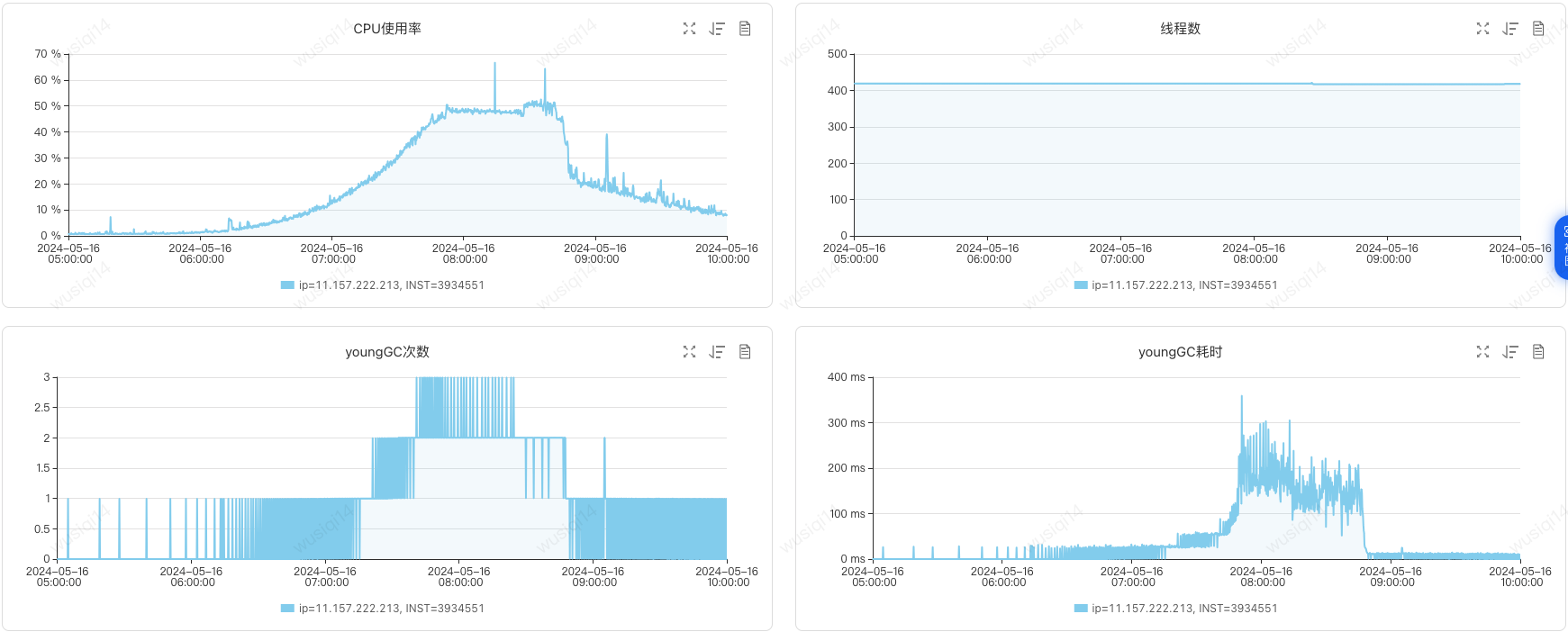

分析GC日志看到new threshold = 6(动态年龄判断,对象的晋升年龄阈值为6),对象仅经历6次Young GC后就晋升到老年代,这样老年代会迅速被填满,直接导致了Full GC。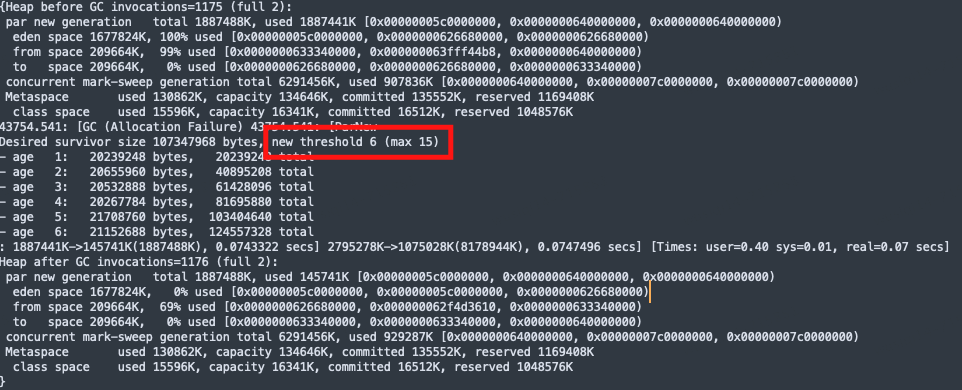
尽管我们配置了晋升到老年代阈值(MaxTenuringThreshold),但在这种情况下,年龄1+年龄2+年龄3+年龄N的对象加起来的空间,大于survivor区域的一半时,就会让年龄N和年龄N以上的对象进入老年代。根本问题还是年轻代堆内存配置比较小。
处理
现在线上堆内存配置是6G,年轻代老年代比例为1:2,也就是年轻代会分配2个G的大小。目前将年轻代老年代比例调整为1:1,也即为年轻代分配3个G的内存。

